GPT大模型技术浅析及其在视频领域的应用
ChatGPT (Chat Generative Pre-trained Transformer )自问世以来,便展现出了令世人惊艳的对话能力。仅用两个月时间,ChatGPT 月活跃用户就达一亿,是史上用户增速最快的消费应用。这一现象级突围产品的横空出世,拉开了大语言模型(Large Language Models, LLMs)产业和生成式AI(AIGC)产业蓬勃发展的序幕。

有分析报告统计称,中国大语言模型产业已分化出通用基础大模型、垂直基础大模型、应用开发和工具层厂商四大类。在全球政治经济局势下,自主可控是保障网络安全、信息安全的前提,自研基石模型具有高度战略意义。可以大胆假设,未来若形成大模型能力领先,谁就更有可能拥有从应用层到算力层的营收话语权。
所以毋庸置疑,大模型产业的蓬勃发展将助力AI工业化进程、变革海量应用交互方式、创造数字产业新的增长空间。从国家、企业到个体都需立足长远,迎接AIGC与通用人工智能(AGI)时代的到来。
通用基础大模型的突破
语言模型是一种人工智能模型,通过一种统计方法来预测句子或文档中一系列单词出现的可能性的机器学习模型,他被训练成理解和生成人类语言。在机器学习模型中,参数是历史训练数据中机器学习模型的一部分。“大”在“大语言模型”中的意思是指模型的参数量非常大。大模型具有庞大的参数规模和复杂程度的机器学习能力。它能提供更强大、更准确的模型性能,以应对更复杂、更庞大的数据集或任务,也能够学习到更细微的模式和规律,具有更强的泛化能力和表达能力。

相比之前的生成式对话产品,ChatGPT在大范围连续对话能力、生成内容质量、语言理解能力和逻辑推理能力上都得到大幅提升,是AIGC极为关键的发展节点。“Chat”指向它的功能,“Generative”代表它属于生成式算法。生成式算法在过去数年中受制于循环神经网络(RNN)的内生缺陷始终发展缓慢,直到2017年 “Transformer”架构出现并解决了传统RNN模型的问题,生成式AI才开始在预训练的Transformer架构之上焕发生机,自然语言处理(NLP)、计算机视觉(CV)甚至多模态领域通用基础大模型飞速演进。在模型参数量几何级数增长以及多种训练方式的探索之中,ChatGPT横空出世,也标志着通用基础大模型将突破NLP领域以小模型为主导的传统发展范式。
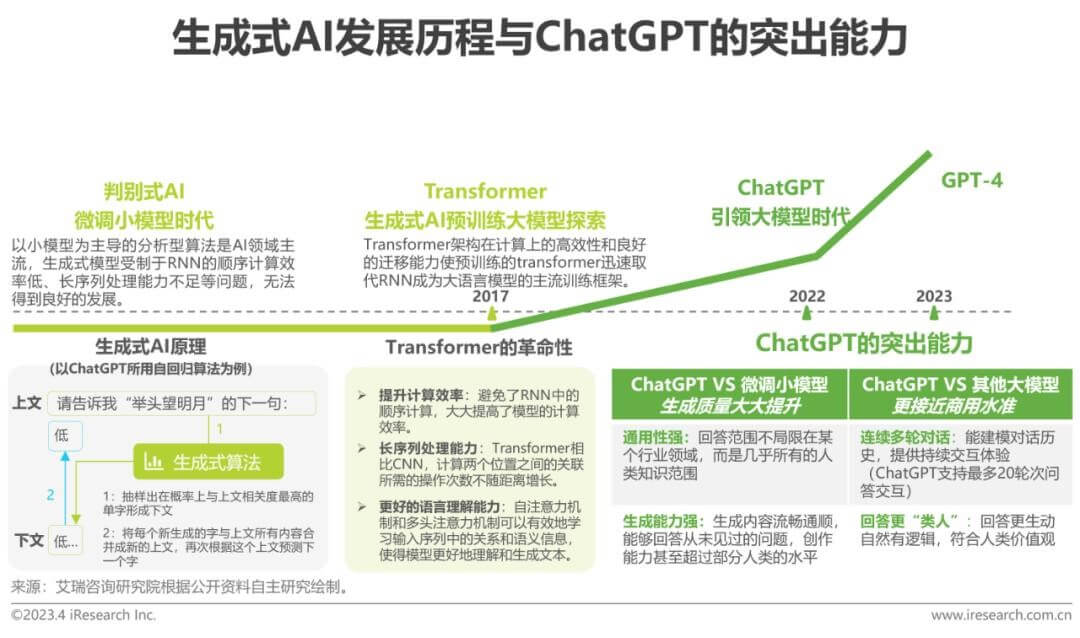
GPT大模型是一种深度学习模型,采用了Transformer架构,可用于自然语言处理任务。它通过大规模的预训练过程,从大量的互联网文本中学习语言的统计规律和语义关联。在预训练过程中,GPT能够通过多层自注意力机制捕捉长距离依赖关系,并且能够有效地建模上下文信息。
简单来讲就是用大数据模型和算法进行训练的模型,能够捕捉到大规模数据中的复杂模式和规律,从而预测生成更加准确的结果。就好比我们在海里(互联网上)捞鱼(数据),捞很多的鱼,然后把鱼都放进一个箱子里,逐渐形成规律,最后就能达到预测的可能,相当于一个概率性问题,当这个数据很大很大量时,并且具有规律性,我们就能预测可能性。它的能力归根于RHLF指令精调+能力涌现,让大模型说好“人话”。
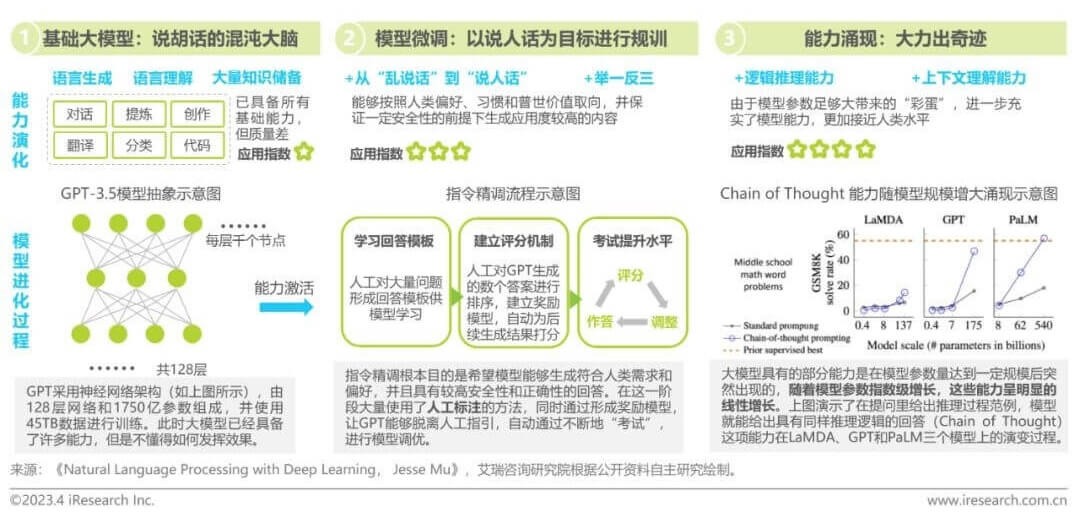
除此之外,大规模语言模型基座的可扩展性很强,其能够很容易和外部世界打通,源源不断地接受外部世界的知识更新,进而实现反复自我迭代。因此,大规模语言模型是为ChatGPT等生成式人工智能应用程序提供支持的人工智能(AI)的一项关键进展,也被看作是实现通用人工智能的希望。
GPT大模型在视频领域的应用
GPT大模型使应用程序能够创建类似人类的文本和内容(图像、音乐、视频等),并以对话方式回答问题。各行各业的组织正在将GPT模型和生成式人工智能用于问答机器人、文本汇总、内容生成和搜索。他还可用于自动化和改进各种任务,从语言翻译和文档摘要到撰写博客文章、构建网站、设计视觉效果、制作动画影视视频、编写代码、研究复杂话题,甚至创作诗歌。这些模型的价值在于其速度和运行规模。例如,您可能需要几个小时来研究、剪辑一个指定内容的视频,而GPT大模型只需几秒钟就能生成一个短视频。
尤其是OpenAI在今年2月16日凌晨发布了王炸的文生视频大模型Sora,它能够仅仅根据提示词,生成60s的连贯视频,“碾压”了行业目前大概只有平均“4s”的视频生成长度。

Sora生成的东京街头场景视频
文生视频大模型Sora的功能包括:
(1)文本到视频生成能力:Sora能够根据用户提供的文本描述生成长达60s的视频,这些视频不仅保持了视觉品质,而且完整准确还原了用户的提示语。
(2)复杂场景和角色生成能力:Sora能够生成包含多个角色、特定运动类型以及主题精确、背景细节复杂的场景。它能够创造出生动的角色表情和复杂的运镜,使得生成的视频具有高度的逼真性和叙事效果。
(3)语言理解能力:Sora拥有深入的语言理解能力,能够准确解释提示并生成能表达丰富情感的角色。这使得模型能够更好地理解用户的文本指令,并在生成的视频内容中忠实地反映这些指令。
(4)多镜头生成能力:Sora可以在单个生成的视频中创建多个镜头,同时保持角色和视觉风格的一致性。这种能力对于制作电影预告片、动画或其他需要多视角展示的内容非常有用。
(5)从静态图像生成视频能力:Sora不仅能够从文本生成视频,还能够从现有的静态图像开始,准确地动画化图像内容,或者扩展现有视频,填补视频中的缺失帧。
(6)物理世界模拟能力:Sora展示了人工智能在理解真实世界场景并与之互动的能力,这是朝着实现通用人工智能(AGI)的重要一步。它能够模拟真实物理世界的运动,如物体的移动和相互作用。
可以说,Sora的出现,预示着一个全新的视觉叙事时代的到来,它能够将人们的想象力转化为生动的动态画面,将文字的魔力转化为视觉的盛宴。Sora正以其独特的方式,在这个由数据和算法编织的未来,重新定义着我们与数字世界的互动。
再说回GPT大模型,它在视频视听特效的生成和处理中也有着重要作用。通过对大量影视作品以及特效技术的学习,GPT可以生成出更加丰富和惊艳的视听特效,为视频制作带来了更多的可能性和创新。同时,GPT模型还可以通过对音频信号的分析和处理,提高视频的音效质量和后期制作效率,为视频的视听效果提供更好的保障。

此外,在安防监控方面,GPT大模型在视频监控场景中可以通过对图像和声音的分析,实现目标行为识别和异常检测等功能,对事件的分类和预测,实现智能化的决策支持和应急响应告警等。



